






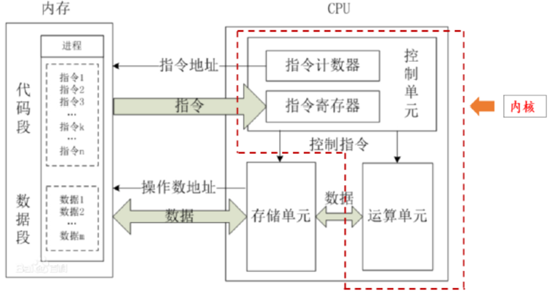
结构、电磁、多物理场仿真计算相关的CPU指令集、硬件配置推荐
结构、电磁、以及多物理场仿真计算对计算精度和性能要求非常高,往往涉及大规模矩阵运算、迭代求解器和并行计算。这些仿真应用依赖处理器支持的浮点运算优化指令集来提升效率。
(一)仿真计算相关的CPU指令集
1. AVX(Advanced Vector Extensions)系列
适用于 x86 架构(Intel 和 AMD),是目前科学计算和仿真领域的主力指令集。
- AVX / AVX2:支持 256 位向量计算。常用于线性代数、矩阵乘法、求解 PDE(偏微分方程)。
- AVX-512:512 位宽的向量寄存器,进一步提升浮点运算效率。
- 用途:大型有限元分析(FEA)、计算流体力学(CFD)、多物理场仿真。
- 优势:在高维矩阵和大型网格计算中加速明显。
- 应用软件:ANSYS、ABAQUS、COMSOL 等仿真工具在支持的 CPU 上会调用 AVX-512 指令。
2. FMA(Fused Multiply-Add)指令
FMA 指令允许在一次时钟周期内完成乘法和加法运算,提高浮点运算密度。
- 用途:适用于求解非线性方程组、最小二乘法优化、以及多重积分等复杂计算。
- 应用场景:在电磁场仿真(如 Maxwell 求解器)、结构仿真中的刚度矩阵求解中广泛使用。
3. ARM 指令集(NEON 和 SVE)
随着 ARM 在 HPC 领域的崛起,部分仿真工具也开始支持 ARM 架构。
- NEON:128 位向量扩展,用于小规模仿真和移动端仿真工具。
- SVE(Scalable Vector Extensions):动态向量长度设计,适用于科学计算和并行仿真。
- 用途:多物理场耦合仿真、电池管理系统建模(如新能源电动车中)。
4. RISC-V(RVV 向量扩展)
- RVV(RISC-V Vector Extension):支持可变长度的向量计算,适合灵活定制的仿真系统。
- 用途:实验室自研算法、专用物理仿真,如新材料和复杂耦合场问题。
不同 CPU 厂家对指令集支持的情况:
- Intel:支持 AVX2 / AVX-512,适合复杂结构和多物理场仿真。
- AMD:支持 AVX2,部分新架构也逐步支持 AVX-512。
- ARM:SVE 逐步用于 HPC 和电磁仿真场景(如超算系统)。
关键匹配指令集与仿真领域
|
仿真类型 |
关键指令集 |
典型应用 |
|
结构仿真(FEA) |
AVX/AVX-512, FMA |
刚度矩阵求解、大规模线性方程组 |
|
电磁仿真(EM) |
AVX,NEON,FMA |
Maxwell 方程求解、电感器优化 |
|
多物理场仿真 |
AVX-512, SVE, FMA |
耦合分析(电-热-流体等多场联动) |
AVX 系列在大型结构仿真和 CFD 计算中是主力,而 FMA 和 SVE 在高密度运算及电磁场仿真中表现优异。如果需要更多关于具体软件如何利用这些指令集的信息,我可以进一步查找或分析相关资源。
(二)intel和AMD支持AVX和FMA指令集在仿真计算应用
Intel和AMD在AVX-512和FMA指令集上的差异主要集中在支持的广度、实现方式、性能优化和用途方面。尽管这两家公司都提供高级矢量扩展(SIMD)指令来加速浮点计算和并行计算,但它们的具体实现方式和目标平台有所不同。
1. AVX-512:支持情况和差异
AVX-512是Intel推出的SIMD指令集,旨在加速深度学习、科学计算和高性能计算(HPC)任务。
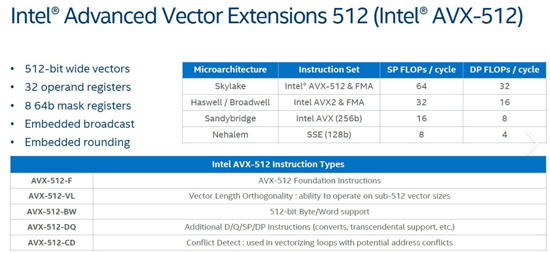
- Intel 的实现:
- 全面支持:大多数Xeon和Core-X系列处理器(如Cascade Lake、Ice Lake等)都支持AVX-512。
- 多种子集:Intel根据不同的处理器系列,提供了多个AVX-512子集(如 AVX-512F、AVX-512VL、AVX-512DQ 等)。
- 硬件特性:高带宽和双倍寄存器(512位),允许一次处理更多数据。
- 功耗与频率问题:启用AVX-512时,处理器频率会下降,以防止过热和功耗增加,这可能导致在某些工作负载下性能波动。
- AMD 的现状:
- 不完全支持:截至目前,AMD的桌面或服务器CPU尚未正式支持完整的AVX-512指令集。部分新一代 Zen 4架构(如EPYC Genoa)支持部分AVX-512指令,但没有Intel的全面实现。
- 兼容性和功耗考量:AMD选择在一些情况下忽略AVX-512,专注于平衡功耗与性能,认为AVX-256等现有指令足以应对大多数任务。
Intel在更广泛的领域内提供了完整的AVX-512支持,并针对HPC和AI优化。然而,AVX-512的频率下降问题让一些开发者诟病。AMD则对AVX-512持谨慎态度,更注重高效的AVX2和FMA实现。
2. FMA(Fused Multiply-Add):支持情况和差异
FMA指令允许一次执行乘法和加法,减少计算步骤,是加速矩阵运算和AI推理的重要工具。
- Intel 的支持:
- Haswell及之后的所有CPU都支持FMA3。
- 支持广泛的浮点计算任务,在数学库、AI模型、物理仿真等领域都有出色表现。
- AMD 的支持:
- Zen架构及之后的所有CPU支持FMA3,但不支持较早的FMA4指令(FMA4仅在一些旧款Bulldozer架构上存在)。
- AMD在多核性能优化上表现出色,Zen架构针对并行任务进行了深度优化,使得在FMA使用密集的多线程工作负载中有时超过Intel。
Intel和AMD公司都支持FMA3,但AMD的FMA4指令集已经被废弃。总体来看,两者在FMA实现上没有明显的功能差异。
3. 性能与功耗取舍
- Intel:AVX-512可以在AI训练和科学计算中提供更高的吞吐量,但由于频率下降,在普通应用中的表现不总是优于AVX2。
- AMD:更倾向于在Zen架构中优化多核性能和能效,在常规并行计算中保持稳定高效。
使用建议
- 选择Intel:如果你的工作负载依赖于AI推理、大规模矩阵计算或HPC应用,并且能容忍较高的功耗,那么Intel的AVX-512是更好的选择。
- 选择AMD:如果你更注重高并发任务、功耗平衡和性价比,AMD的AVX2和FMA3实现将提供更高效的表现。
汇总
- Intel在指令集支持上更激进,提供完整的AVX-512生态,但存在功耗和频率折损问题。
- AMD则选择了功耗和性能之间的平衡,在FMA和AVX2的性能上表现出色,而AVX-512的支持仍处于有限状态。选择哪种平台取决于你的具体应用需求和对能效的考量。
结构/流体/多物理场/电磁仿真最快最完美工作站集群24v2
https://xasun.com/article/a2/2461.html
最新流体动力学、空气动力学、结构动态仿真计算工作站、集群硬件配置推荐24v2
https://www.xasun.com/news/html/?2797.html
2024年电磁仿真HFSS单机/虚拟加速/集群硬件配置推荐
https://www.xasun.com/article/102/2525.html
Comsol Multiphysics多物理场耦合仿真工作站、集群硬件配置方案24v3
https://www.xasun.com/news/html/?2851.html
我们专注于行业计算应用,并拥有10年以上丰富经验,
通过分析软件计算特点,给出专业匹配的工作站硬件配置方案,
系统优化+低延迟响应+加速技术(超频技术、虚拟并行计算、超频集群技术、闪存阵列等),
多用户云计算(内网穿透)
保证最短时间完成计算,机器使用率最大化,事半功倍。
上述所有配置,代表最新硬件架构,同时保证是最完美,最快,如有不符,可直接退货
欲咨询机器处理速度如何、技术咨询、索取详细技术方案,提供远程测试,请联系
咨询微信号:
UltraLAB图形工作站供货商:
西安坤隆计算机科技有限公司
国内知名高端定制图形工作站厂家
业务电话:400-705-6800



